

A lot of news articles and tweets are very similar to each other in content - we would know, as we process over 1 million of them a day!
Unfortunately, this similarity can make research tedious. It is wasteful to read essentially the same story 5 times. Our solution is Similar Story Grouping.
How it works
Our machines cluster pieces of content together based on more than 1000 dimensions, then decide which story is the most representative of the cluster. The resulting stories are then run through the same process to narrow down the results until we come to a reasonable number of outputs for humans to read.
At that point, the remaining stories are served to users as "representatives" of the whole group of similar content. The content that was not ultimately labelled as representative is considered a "similar story" for that group.
It even finds similar content between various languages:
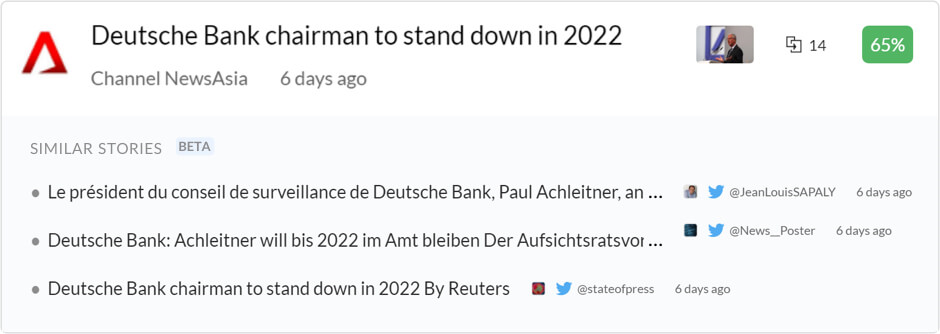
Different display options
There are two display options you can change for similar stories:
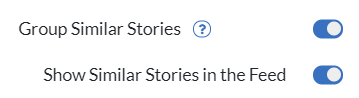
Group Similar Stories
By default, similar stories are grouped together. This means the representative story mentioned in the How it works section is the only piece of content displayed. All related stories are hidden from the feed, so you won't have to see repetitive content.
If you turn this option off, the content from all similarity clusters will be treated as standalone content, and each piece will be displayed individually in the feed. This is how most less-sophisticated news platforms are set up, but it means a lot of repetitive content that adds no value for the user.
Show Similar Stories in the Feed
If you still want to look through the headlines and view the content that was not representative, you can still show the titles of those stories in a simple, compact textual format.
Turn this option on and look under the representative story to see the headlines, titles, and publications of other content in the similarity cluster. This is useful for skimming headlines and sources to find other sources or slightly different ways of wording a story. Occasionally this can give you a more rounded idea of the situation, especially if the topic is controversial or the reality is somewhat unclear.
Implemented in C++ for scalability
The entire Similar Stories pipeline requires immense computational resources. The regular CityFALCON pipeline processes over 1 million pieces of content per day, then every one of those pieces of content must be matched against all the others, including past content, to calculate similarity.
To benefit from as much computational efficiency as possible, we settled on implementing Similar Stories processing in C++. Unlike languages such as Ruby or Python, C++ has lower overhead and commands full flexibility in directing exactly how to handle memory resources. This enables precise memory management, which is essential for large data computation. Furthermore, C++ compiling is direct to native processor code, minimising overhead and resource usage.
All of this ensures the compute-intensive Similar Stories component of CityFALCON can scale along with the rest of our services and features, so both high-volume API users and low-volume retail consumers experience smooth and accurate delivery.